If you’ve ever cracked a hash with hashcat, you’ll know that sometimes it will give you a $HEX[0011223344] style clear. This is done to preserve the raw byte value of the clear when the encoding isn’t known (or there’s a colon “:” character).
Investigation
Driven by an inability to crack the majority of a certain set of hashes I suspected were in a foreign charset, I decided to have a closer look at what was going on. Let’s take a look at the following examples:
$HEX[5370e4746a6168723230]$HEX[4ca3744d65496e313233]$HEX[4a6f686e31303a3130]
I figured these were probably just extended UTF-8 bytes, so I tried to decode them first using this:
for x in $( cut -d\[ -f2 potfile | tr -d ] ); do
echo -n $x \
| xxd -ps -r \
| iconv -f utf8
echo
doneThe cut & tr commands remove the $HEX[], then the echo -n makes sure we don’t get a newline added. xxd reverses the byte numbers to actual bytes, and finally iconv does the conversion (to utf-8 in this case).
This produced the following errors:
Sp
iconv: (stdin):1:2: cannot convert
L
iconv: (stdin):1:1: cannot convert
John10:10As you can see, only the last one decoded properly. That’s because it’s actually just standard ASCII, but has a colon : in it, and hashcat hexifies that so you can be certain that the visible colon in the potfile actually separates the hash and the clear text password. But the first two didn’t work.
Encoding matters
I did some digging around and tried to figure out what encodings Windows supported, and in particular, would be supported both from a GINA (i.e. the login screen) perspective and in the actual mechanics of the NT hashing algorithm. It turns out the NT hash UTF-16LE encodes values it gets, so I tried that:
for x in $( cut -d\[ -f2 potfile | tr -d ] ); do
echo -n $x \
| xxd -ps -r \
| iconv -f utf-16le
echo
doneThe only thing I changed here is utf8 -> utf-16le specification for iconv. This time it looked like it worked!

I knew that last password was actually a bible verse with a colon, so there were clearly different encodings at play, or so I thought, and I wrote a simple script that takes the hex string from hashcat’s output, then tries to decode it first as UTF8, and if that fails UTF16, then UTF32.
!/usr/bin/env python3
from sys import argv
from re import search
hexstr=argv[1]
if hexstr.startswith('$HEX['):
hexstr = search('^\$HEX[([0-9a-f]+)]$', hexstr).group(1)
try:
print(bytes.fromhex(hexstr).decode('utf-8'))
quit(8)
except UnicodeDecodeError:
try:
print(bytes.fromhex(hexstr).decode('utf-16'))
quit(16)
except UnicodeDecodeError:
try:
print(bytes.fromhex(hexstr).decode('utf-32'))
quit(32)
except UnicodeDecodeError:
print(bytes.fromhex(hexstr).decode('utf-8',errors='replace'))That looked promising, I was clearly getting what looked like legit passwords. I was surprised to see so much Japanese lettering in there, but ok it is what it is.
Windows Codepages
The logical next step then was to look into cracking foreign UTF charsets. This lead me to Netmux’s cracking book, which had snippets like this in there for different languages (copied as is):
Arabic UTF8 (d880-ddbf) hashcat -a 3 -m #type hash.txt --hex-charset -1 d8d9dadbdcdd -2 80818283848586 8788898a8b8c8d8e8f909192939495969798999a9b9c9d9e9fa0ala2a3a4a5a6a7a8a9aaabacadae afb0blb2b3b4b5b6b7b8b9babbbcbdbebf -i ?1?2?1?2?1?2?1?2
This threw me for a bit. First because of the line breaks, but more importantly, whatever the heck they did that selectively encoded 1 (i.e. the number one) as l (i.e. the letter ell) in the byte charset. It should be:
hashcat -a 3 -m #type hash.txt --hex-charset -1 d8d9dadbdcdd -2 808182838485868788898a8b8c8d8e8f909192939495969798999a9b9c9d9e9fa0a1a2a3a4a5a6a7a8a9aaabacadaeafb0b1b2b3b4b5b6b7b8b9babbbcbdbebf -i ?1?2?1?2?1?2?1?2
If you’re interested in what’s going on, it’s brute forcing the UTF8 arabic hex space as bytes (i.e. bytes 0xd880 to 0xddbf).
This netted not a single hash. :( There’s some work to still be investigated here using mode 900 to bypass the UTF-16LE encoding, but I got stuck getting my kernels to work and decided to come back to it later.
Then, a tweet from FakeUnicode lead me to Windows Code Pages, otherwise known as, or at least entered as Alt-Codes. In particular CP1251 (yes, it’s a mistake, you’ll see). I switched iconv to use CP1251 (the -f switch) and the output set to UTF-8 (the -t switch) and got:
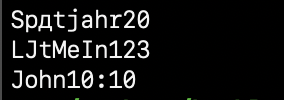
Whoa! It turns out I didn’t have a bunch of Japanese lettering, I had just been decoding it wrong! But something still didn’t look right, after some poking, I realised I had used CP1251 (Cyrillic) instead of CP1252, the more common European language one. I leave this mistake in as a warning to others. Rerunning it with the the right code page set got me:
Spätjahr20 L£tMeIn123 John10:10
That looks way more likely! But, I should make it clear that you won’t know what encoding was used, unless you know the locale of the user’s machine that generated it. Each of those passwords could be using a different code page! The context of the organisation they come from will help.
A Better Brute
Finally, I tried changing the hashcat charset byte bruteforce to use the whole printable code page for the locale I was targeting, using the same technique as netmux’s original (minus a few unlikely characters starting with bytes 01, 02 and 21). Much like the original this is inefficient and will generate 447 bytes rather than the 220 we’re actually targeting.
hashcat -a 3 -m 1000 hash.txt --hex-charset -1 000620 -2 090B0C131418191A1B1C1D1E1F202122232425262728292A2B2C2D2E2F303132333435363738393A3B3C3D3E3F404142434445464748494A4B4C4D4E4F505152535455565758595A5B5C5D5E5F606162636465666768696A6B6C6D6E6F707172737475767778797A7B7C7D7E8688919298A2A3A4A5A6A7A8A9ABACADAEAFB0B1B2B3B4B5B6B7B8B9BABBBCBDBEC1C6D2D7E0E2E7E8E9EAEBEEEFF4F7F9FBFC
Alternatively, if you only want the more efficient foreign character bytes, you can use:
--hex-charset -1 06 -2 0C1B1F2122232425262728292A2B2C2D2E2F303132333435363738393A404142434445464748494A4B4C4D4E4F505152797E86889198A9AFBABEC1D2
However, the better way is to put the specific characters in a hashcat .hccr charset file (you can grab it from this gist). Typically, hashcat only puts the language specific characters in there for some reason, but a user could use any of the printable characters from that code page, so I included them all. You can use it like this:
hashcat -a 3 -m 1000 hash.txt -l ar_cp1256_full.hccr ?1?1?1?1?1?1?1?1 -i
You can also rely on slow full-byte keyspace brute forces (pairs of ?b?b) when you aren’t sure what code page is in use.
The Detail
If you want to understand what’s happening in more detail, consider the following bytes:
4bf67374657231393634
iconv shows the result in UTF-8, assuming CP1252 as the input charset, as:
> echo 4772f6df6572657231 \ | xxd -ps -r \ | iconv -f cp1252 -t utf8 Größerer1
Most of that is normal ASCII, but the third byte 0xf6 is decimal 246, which you can lookup here (search for 0246, not 246) and see that it corresponds to “ö”.
This is why hashcat gives you the clear in hex, not ASCII or UTF-8, because it doesn’t know which encoding was used by the OS.
Conclusion
I hope this taught you something about how NT hashes and codepages interact, how hashcat deals with them, and how to debug them.