When I got a new MacBook with an M1 Pro chip, I was excited to see the performance benefits. The first thing I did was to fire up hashcat which gave an impressive benchmark speed for NT hashes (mode 1000) of around 9 GH/s, a solid doubling of the benchmark speed of my old Intel MacBook Pro. But, when it came to actually cracking things, the speed dropped off considerably. Instead of figuring out why, I decided to try my hand at writing my own NT hash cracker, because I’m kind of addicted to writing single use tooling in rust then taking time to perf optimise it.
If you’re only interested in the results, here it is, under a variety of scenarios against hashcat, and you’ll see it ranges from waaay faster to much faster than hashcat. You can get the code at https://github.com/sensepost/ltmod/ in the ntcrack directory.
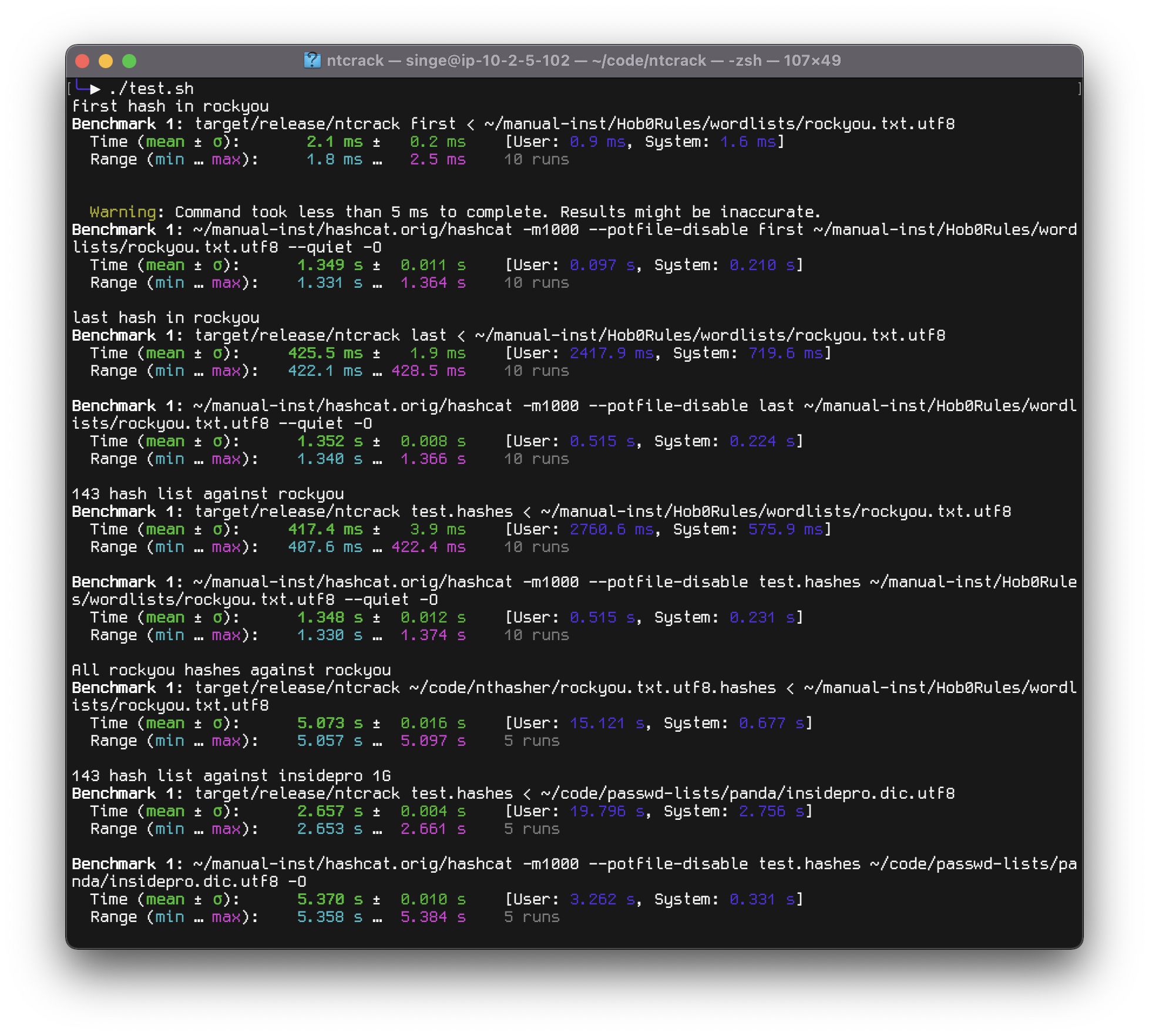
(If you’re wondering why there’s no hashcat run for the full rockyou hashes as input, it’s because it takes about 10m with hashcat.)
I optimised for total running time, and got some good gains against hashcat by a faster startup. But even if we look at raw hashes generated per second, when cracking the 143 test hashes against the 1G sized insidepro wordlist, hashcat gets 26 205 kH/s while ntcrack gets 40 207 kH/s.
In this post, I’ll go through what I did that worked, and didn’t work to get this result.
But Wait You Didn’t …
The first response to this sort of work and comparison always seems to be to suggest shifting the goalposts to a different comparison, oft times driven by a belief this is some sort of fight, so let me get all the caveats out of the way.
Hashcat is amazing, not just the tool, the project and the community around it is too. In terms of total functionality, hashcat thrashes my little project into a little whimpering mess. They support a bajillion different hashes, and a bajillion different ways to crack them. For NT hashes and other fast hashes, they have a ton of rules and other manipulations that can be used. In fact, the second you throw a simple mutation to brute force an extra ASCII byte (?a) on the end of each word (-a6) in the wordlist, hashcat hits 900+ MH/s, which also thrashes the hashes per second, *and* total running time of ntcrack.
So this isn’t a “hashcat bad, me good” post.
What is it
ntcrack is a simple rust program, weighing in at around 150 lines of code. It runs multi threaded on CPU only, no GPU. It reads a list of input hashes to crack from a file, and a wordlist to check the hashes against from stdin. So you run it like this:
./ntcrack input.hashes < wordlist
It’s rough and ready right now. No error handling. Expects a wordlist with unix line breaks, you can’t specify the number of threads, and doesn’t even let you pipe the wordlist. I’ll get to that … maybe … pull requests welcome.
The Actual Post – What Did I Learn
I’ve commented the code so you can see what I did to speed things up, but it doesn’t really give you what the alternatives are, and which I tried. In the next section I’m going to go through each of those, in roughly descending order of impact i.e. I’ll start with what made stuff go the fastest not the order I actually built it.
Multi-threading
Multi-threading is an obvious way to speed something up. Especially for large scale brute forcing like this, we should just be able to parallelise the tasks and get an instant speed up. But it doesn’t always work like that.
The main problem with password cracking is first to write an optimised hash generator, but second to feed it from the wordlist fast enough. So if you head to threading too soon, you’ll either end up with an inefficient hash generator that threading would hide a little, or you end up constrained waiting for the data to be read from the file.
As I spent a lot of time working on getting the hashing fast first, by the time I got to threading I didn’t have that problem, but I did have the other … simple threading made stuff *slower* because the threads sat around waiting for things to be read and fed to them.
Threading in rust is hard, if you follow the “Rust by Example” guide (https://doc.rust-lang.org/rust-by-example/std_misc/channels.html) you quickly run into a protracted battle with the borrow checker. Steve Klabnik has a perfect write up of why here (https://news.ycombinator.com/item?id=24992747). Because rust’s borrow checker stops you from being a bonehead, it also makes it very hard to share data between threads (I’m not even talking write here). I tried his suggestion in the end, scoped threads, and it made things slower due to the read problem. I then tried the Rayon crate (https://docs.rs/rayon/) and it’s par_iter() which made things less slow than scoped threads but still slower than no threads. So I decided to build my own raw threading approach.
I moved all the logic for generating the hash and comparing it to a thread, and kept as little in the read_line_from_file loop as possible, to maximise read speed (i.e. read and send to the thread, then read the next line). I also used a multiple receiver single sender channel from the crossbeam crate (https://docs.rs/crossbeam/latest/crossbeam/channel/index.html) to implement a sort of queue that the threads could pick work from as fast as I could read it. I used crossbeam because the standard channel (https://doc.rust-lang.org/std/sync/mpsc/) is a multi-producer, single-consumer, which is the opposite of what I needed.
The big stumbling block was that what was read from the file went out of scope when the program ends, and the threads don’t. Rust’s compiler isn’t smart enough to spot that we wait for all the threads to exit at the end, so you have to instead stick each line in a new object for each thread, which means an expensive allocation. So instead I buffered a bunch of words into a single array (Vec) and sent a buffer to a thread to work through to both reduce the alloc()s as well as the amount of messages that needed to be sent and pickup over the channel.
Lastly, I wanted to be able to exit early if all the hashes supplied had been cracked; don’t waste time reading the rest of the file and generating hashes for them. This is why the first item in the test screenshot at the top of this post is so fast. But, each thread doesn’t know what the other threads have cracked, and introducing a shared, writable list was going to cause more blocking than it’s worth. So instead I send the number of hashes a thread has cracked back, and the main program checks if the total matches. That required some caching, as sending a message for every cracked hash introduced a significant slowdown on large input hash lists. So instead I buffer and send them through in chunks.
Reading a file … fast
You would have seen multiple references to file read speed above. That’s because with a fast hash like an NT hash, you’re likely to get large wordlists thrown at the input hashes (and less likely to get large input hash lists), so the thing that needs to be optimised the most is the file read speed.
For this I tried numerous options. The first was a vanilla lines() iterator which is what the “Rust by Example” documentation suggests (https://doc.rust-lang.org/stable/rust-by-example/std_misc/file/read_lines.html). This is very slow, primarily because it allocates a new String for each line, or so my bad reading of perf data tells me.
I then tried a few different versions of implementing my own line reader, all of which worked out either slower or only marginally faster. Until I was pointed to ripline (https://twitter.com/killchain/status/1482770333958553603) and (https://github.com/sstadick/ripline). Ripline takes its implementation from ripgrep, and has a few different ways of reading from a file. The one I was most interested in was it’s use of the mmap() (https://www.man7.org/linux/man-pages/man2/mmap.2.html) call, which in their benchmarking was the fastest way to read from a file and still get it line by line.
I of course tried several variations, including my own mmap reader, using mmap with other line readers etc. but ripline gave me the fastest iterator over a mmap’ed file. I also noticed that it was marginally faster getting the file from stdin rather than a filename. But ripline + mmap2 worked the best. The only downside is that it breaks DTrace profiling (https://gist.github.com/singe/70010e2f48a7ad8fdcbab177eeb9b18a).
Hash lookups
You’d think the most expensive part of cracking a single hash would be generating the candidate hash, but it’s not, it’s finding if the candidate hash you generated is in the list of input hashes you provided. If you only provide one input hash, then it isn’t a problem, but if you provide thousands or hundreds of thousands, you have to look up every candidate hash generated against this list. To take it a bit further, if you have 10 input hashes, the average linear search through that list will find a hash in 5 attempts. So if you have a wordlist with 100 hashes, now you’re doing 100*5 =500 lookups. But, given that the majority of hashes you generate *won’t* be in your input list, the performance is actually much worse.
My first attempt was to use some sort of balanced tree. Rust has some built in BTree functionality (https://doc.rust-lang.org/std/collections/struct.BTreeMap.html) and I used that (BTreeSet). This gave a bit of a speedup for larger input hash lists. However, it wasn’t what I hoped. I experimented with removing items from the set to speed up future lookups and allow an early exit if we cracked everything, but it still wasn’t what I hoped.
Then a friend pointed out I could just use a hash table (https://doc.rust-lang.org/std/collections/hash_map/struct.HashMap.html) because it gives a constant O(1) cost for each lookup, rather than a BTree’s O(log(n)). That worked well and gave a bit of a speed up.
But what really made the impact, was to switch the HashMap’s hasher function to the NoHashHasher (https://docs.rs/nohash-hasher/0.2.0/nohash_hasher/index.html), a hasher specifically designed for already hashed data, which a list of NT hashes is! With that in place, I got a great combined speed boost when looking up whether a hash generated from a word in the wordlist matched any of the input hashes provided.
Finally, I did one more thing. If only a single input hash is provided, it’s faster to check if a candidate hash starts with the same bytes as the hash we’re looking for, rather than comparing all 16 bytes of the two hashes. If they don’t match we can move on and save the slightly more expensive HashMap lookup. And if they do, it’s a very small extra price to pay. But this has the added advantage, that for small input hash lists, we can reduce the total HashMap lookups we do to the number of unique first bytes. Given there are a total of 256 possible byte values, for input hash lists much larger than that it doesn’t start to make sense. The small number of all possible single bytes means we can store the byte in an array of 256 items, and do a very fast lookup by using the byte as the index. e.g. if the hash starts with ‘AA’ then our boolean array[170] (170 is the decimal of the hex AA) can be set to true.
The Actual Hashing
Finally, we want to make sure the actual hash computation is efficient. A NT hash has two operations, encoding the text in UTF16LE then MD4 hashing the result. The latter part turned out to be pretty easy. The Rust Crypto team (https://github.com/RustCrypto) has done a great job in building performant algorithms in rust and MD4 is no exception (https://docs.rs/md4/latest/md4/). One small tweak was to do the digest in one call, rather than an update and then finalise call as per their docs.
What took longer to get right, and I didn’t see coming, was the UTF16 encoding. At its most simple, UTF16 will just widen an ASCII character to two bytes instead of one by adding a NULL byte. The “LE” stands for little endian, which will place the NULL before the ASCII byte. So an ASCII “A” is 0x41 and a UTF16LE encoded “A” is 0x0041. What hashcat does (did? https://github.com/hashcat/hashcat/commit/045701683430ce0c0a0c1545a637edf7b659a8f3) for speed and to avoid complexity in the GPU code, is to just stuff that NULL byte in, and assume it’s always an ASCII charset in use. I initially tried the same but ran into two problems. The first was that it required alloc()ing a whole new Vec for each candidate we encode, which becomes expensive. This was resolved by doing it per char in a map instead and reusing the resulting Vec. The more pernicious problem is that most wordlists don’t only have ASCII characters and doing proper encoding matters if you deal with non-English hashes.
Rust forces you to be explicit about Strings by enforcing a UTF8 requirement for a String. That’s fine if your input file is guaranteed to be UTF8 encoded, but wordlists are often a mixed bag, and might not be universally encoded. So it makes more sense to read bytes from the file, and not assume you’re reading UTF8. That means that to do “proper” UTF16 encoding you need to first convert the raw bytes to UTF8. After that Rust has native UTF16 encoding (https://doc.rust-lang.org/std/primitive.char.html#method.encode_utf16) which can be converted to little endian bytes natively too (https://doc.rust-lang.org/std/primitive.u16.html#method.to_le_bytes). This works, and is ok speed wise. But, in the end going unsafe() and using align_to() worked much faster. At least half the speed up I suspect is from using unsafe() and dropping some of the checks that brings.
Writing to stdout
This almost always catches me. By default the println! macro is *slow* for writing large amounts of data to stdout. It allocs a String, calls a formatter and flushes the stream (I think). Doing a raw write to the file handle with bytes is much faster. Add in something I learned a few years ago when discussing perf optimisations with Atom (https://twitter.com/hashcat/status/1137335572970790912), use an output buffer. The combination of those two makes a massive speed difference over a basic println!. Then I went down the rabbit hole and squeezed a few more milli seconds by using the write! macro instead of format! or similar to get a printable hex encoding of the resulting hash, doing it per byte instead of across multiple at once, and using extend_from_slice() to add to the buffer rather than push() or append().
The End
That’s it for now. I hope this is interesting to someone else who enjoys going deep on performance issues, or who just needs a fast basic NT hash cracker. Next up, I want to see if I can add the GPUs to the mix … left to my own devices … this is what you get.
After the End? Name clash
ntcrack is already the name of a password cracker circa 1997 (https://seclists.org/bugtraq/1997/Mar/103) that cracks LM hashes (which were used by Windows NT, hence the name). Just for kicks I got it compiled on my machine to test (you can get libdes from https://ftp.nluug.nl/security/coast/libs/libdes/libdes-4.01.tar.gz).

The release mail for v2 states:
“We ran a user list of length 1006 with a word list of around 860,000 in 5 minutes 30 seconds on a pentium 133 with 32MB RAM running Windows NT Server. Roughly 2,606,000 cracks per second..”
So let’s run it on a modern M1 Pro and see how it performs …

That’s a cracking speed of … 1 977 446 H/s which is *slower* than jwilkins’ speed from 25 years ago. But the elapsed time is much faster, 5.5 mins on the pentium for an 860k wordlist, compared with 7.2 seconds for a 14 million wordlist.
Anyway, I hope he doesn’t mind me using the same name :)