One of the things that has often confused me is how little good advice there is for reading large files efficiently when writing code.
Typically most people use whatever the canonical file read suggestion for their language is, until they need to read large files and it’s too slow. Then they google “efficiently reading large files in <lang>” and are pointed to a buffered reader of some sort, and that’s that.
However, in Halvar Flake’s recent QCon talk he had several slides talking about how most code is written based on the old assumptions of spinning disks. With non-SSD HD’s there’s usually a single read head and you can’t do much in parallel. This requires code to optimise for single reads, minimal seeks, and large readahead of data laid out on disk next to each other. But modern SSDs are much more comfortable with seeks and parallelism.
So I wanted to test it. To do this I wrote five simple rust programs that read data from a large file. To keep it simple, I didn’t do any line reading – just read as much as you can as fast as you can.
The code for each of these is available here.
The strategies
1 – Vanilla
Vanilla is the simplest and based on what you get when you google “reading a file in rust” which points you to this chapter in the rust handbook.
It tries to read the whole file, and convert it into a single String in memory.
2 – IO Read
IO read dispenses with the String conversion and does the same as vanilla but with a raw read into a single byte buffer.
Both (1) and (2) will fail if the file you’re trying to read can’t fit into memory.
3 – Block Read
Block read is a modification of (2) to read the file in 8M blocks instead of trying to read the whole file into memory.
The 8M block size is based on some simple tests I did on my machine.
4 – Buffered Reader
If you google “efficiently reading large files in rust” you’ll likely hit an article pointing you to BufReader. The most common use case is to read lines. Instead this is a slight modification to do block reads instead and keep it consistent with the other approaches.
5 – Thread Reader
Finally, this is a threaded version of (3) where each thread simultaneously opens its own file handle, seeks to its offset and reads a part of the file.
This used to be a “bad idea” – multiple concurrent seeks, and concurrent reads would be slow on spinning disks.
I’m using 10 threads, which is as many cores as my MBP M1 has.
Measuring Methodology
I’m quite simply measuring total execution time of each version when reading a 5G file. I do this using the fantastic hyperfine tool.
I run each test three times to warm up caches, then I do five measured runs. The tests were run on my 2021 MBP with an M1 chip.
Hyperfine gives the mean of the five runs with standard deviation, as well as a min and max. Finally it gives some stats comparing each run.
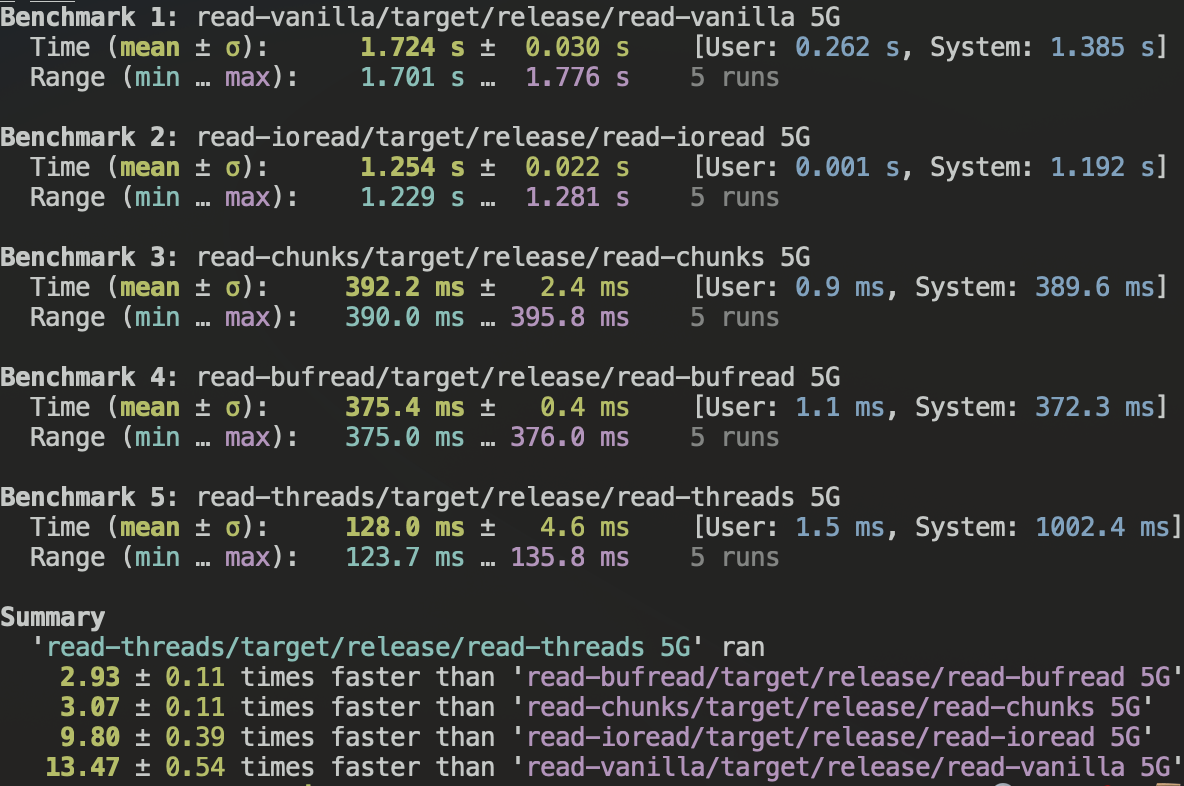
Results
Here are the results of the run. As you can see the vanilla approach is horribly slow. Over 12x slower than the best approach. The IO reader is slightly faster, but not much, because it isn’t needing to mess with String allocations/conversions. There’s a significant speedup reading blocks, and the buffered reader can do this for you and is even very slightly faster than doing it manually. However, when we switch to concurrent reads, we get a significant speed up – nearly 3x faster than the buffered reader.
Conclusion
In short, Halvar was right, which isn’t a very controversial statement. However, I was genuinely surprised to see how big a difference it made, and that there’s little to no discussion on the topic. I hope this helps someone somewhere.