Intro
The last few months I’ve been studying Chrome’s v8 internals and exploits with the focus of finding a type confusion bug. The good news is that I found one, so the fuzzing and analysis efforts didn’t go to waste. The bad news is that I can reliably trigger the vulnerability but I haven’t found a way to weaponise it yet.
If you don’t have prior knowledge of v8, I encourage you to take some time and read through the previous post I wrote. It covers all of the basics regarding the v8 compiler and tools that helped me throughout my research. More importantly, it will help newcomers understand all of the research described within this post.
You can see the TL;DR version of the vulnerability I found in the Chromium bug report: https://bugs.chromium.org/p/chromium/issues/detail?id=1072171. However, if you want to see all the pieces that led to that report, from fuzzing to root cause analysis (including Twitter drama), I encourage you to keep on reading!
Table of Contents
- -0 day – Discovery & set-up
- 0 day – Initial crash and disclosure
- +0 day – Analysis
- Triggering the type confusion
- Patch thoughts
- Conclusions
- Resources
-0 day – Discovery & set-up
In the days prior to the discovery, most of my efforts were spent on understanding Fuzzilli and analysing how to reach interesting parts of v8’s code. If we just decided to launch fuzzers with “out-of-the-box” configurations it’s very likely that we won’t find any vulnerabilities. Fuzzing is a constant race with many other people doing it. Then, if we wanted complete code coverage we’d need a vast amount of resources due to the pure size of v8’s code base. Without complete coverage we wouldn’t get the necessary depth, which is often needed to find complex and exploitable bugs.
Fuzzilli
I was determined to use Fuzzilli, but Fuzzilli relied on patching v8 to convert it into “fuzzable” software, however, a patch for the latest v8 wasn’t available at the time. So, I needed to implement a patch for the latest commit, for which I recently did a Pull Request for the v8 patch here (After this research, the patch and some other bits made it into v8’s code base, so now the only thing that’s needed is to use v8_fuzzilli when generating the build files on the v8 project). The parts of the initial patch were mostly unchanged, the only thing that was needed was to understand the changes on the relevant v8 files and update the Fuzzilli logic accordingly with some added bits that we’ll see later. In any case, all credit goes to Samuel Groß for the initial patch and open-sourcing Fuzzilli!
Intermediate Language
Fuzzilli could be considered to be a context-aware fuzzer. The really neat thing about it is the fact that it implements an Intermediate Language (IL, guess that’s why its called FuzzILli). Examples of this can be seen by having a look at the FuzzIL folder: https://github.com/googleprojectzero/fuzzilli/tree/master/Sources/Fuzzilli/FuzzIL
Having skimmed over the files, you should see that it has the concept of “Programs” which is basically the IL representation within Fuzzilli. The next stop should be the ProgramBuilder file. This file is interesting because it contains the functions used to generate valid JavaScript code, by either generating new code …
public func genIndex() -> Int {
return genInt()
}… or by referencing variables defined somewhere else within the “Program”:
/// Returns a random variable satisfying the given constraints or nil if none is found.
private func randVarInternal(_ selector: ((Variable) -> Bool)? = nil) -> Variable? {
var candidates = [Variable]()
// Prefer inner scopes
withProbability(0.75) {
candidates = chooseBiased(from: scopeAnalyzer.scopes, factor: 1.25)
if let sel = selector {
candidates = candidates.filter(sel)
}
}
...Once a potentially valid program has been generated and mutated, a text file is generated by lifting the program into JavaScript. In essence, Fuzzilli will translate all the IL instructions into their JavaScript counterparts, line by line, ready to be fed into v8.
case let op as LoadBoolean:
output = Literal.new(op.value ? "true" : "false")Targeting the typer
Most of the time while fuzzing, we’ll want to target specific parts of a program by either instrumenting just the parts we want to fuzz, by isolating the portions we want to fuzz or by having test cases that hit that certain part of the code. I tried to aim for a mix of both and, keeping in mind that Fuzilli didn’t take any test cases, did some modifications to, hopefully, target the typer even more.
Through instrumentation
During an internal Friday talk about (Fuzz|Scal)ing, I described my methodology for more effective fuzzing. More specifically, instrumenting only the functionality that we want to target. By doing this (using coverage guided fuzzers such as Fuzzilli), we benefit from the fuzzer generating JavaScript files that focus on a specific part of code, generating more code depth in terms of coverage. After all, that’s the purpose of a coverage guided fuzzer; generate test cases that are likely to hit a larger amount of instrumented code paths. If we narrow down these code paths to aim for depth rather than breadth, the fuzzer will more likely generate outputs that will keep hitting a vertical code path, going into more depth with every mutation.
Improving the methodology
In the past, I used to do the following hack to instrument features or libraries:
- Compile the program without any instrumentation.
- Delete the libraries that I wanted to instrument.
- Generate and compile the deleted libraries with the desired instrumentation enabled.
While this worked in pretty much all of the software I previously fuzzed, it didn’t work on v8. When using the aforementioned workflow we’d get the usual clang errors that relate to undefined symbols at the time of linking libraries, pointing to the fact that certain libraries have been compiled with different flags.

Google Chrome (and by extension, v8) uses ninja to build source code. Google provides great tooling with many options to generate build files such as GN from the depot_tools repository. Running GN will generate the necessary build files with rules. Our little hack here will be to create a ninja build rule to instrument with -fsanitize-coverage=trace-pc-guard, just the parts we want to (refer below to the toolchain.ninja file). These will be all of the “compiler” related parts of v8, since type confusions happen when the JIT (Just In Time) compiler gets triggered and a wrong assumption of a type is made. By taking the following ninja build rule into account we’ll be able to take it as a baseline to create a cxx-instr rule:
$ grep -A 4 "rule cxx" toolchain.ninja
rule cxx
command = ../../third_party/llvm-build/Release+Asserts/bin/clang++ -MMD -MF ${out}.d ${defines} ${include_dirs} ${cflags} ${cflags_cc} -c ${in} -o ${out}
description = CXX ${out}
depfile = ${out}.d
deps = gccWe can now generate said extra rule called cxx-instr that looks like the following, serving as a rule that adds the desired instrumentation:
$ grep -A 4 "rule cxx-instr" toolchain.ninja
rule cxx-instr
command = ../../third_party/llvm-build/Release+Asserts/bin/clang++ -fsanitize-coverage=trace-pc-guard -MMD -MF ${out}.d ${defines} ${include_dirs} ${cflags} ${cflags_cc} -c ${in} -o ${out}
description = CXX ${out}
depfile = ${out}.d
deps = gccAfter creating this rule, all that is left to do is to apply it to whichever libraries we want or need to have instrumentation in, by changing the build rule from cxx to the newly created cxx-instr:
$ grep "cxx-instr.*/typer" obj/v8_compiler.ninja
build obj/v8_compiler/typer.o: cxx-instr ../../src/compiler/typer.cc || obj/v8_compiler.inputdeps.stampWith these modifications, we’ll ensure that only a certain part of v8 gets instrumented, more specifically in our case, the typer.
Through customisation
After instrumenting the code to our liking, we need to ensure that our fuzzing efforts are maximised. Fuzzilli provides two ways to try and trigger JIT on v8; one with the JITStressMutator.swift mutator and another one with the V8Profile.swift profile. For V8Profile there is a code generator:
fileprivate func ForceV8TurbofanGenerator(_ b: ProgramBuilder) {
let f = b.randVar(ofType: .function())
let arguments = b.generateCallArguments(for: f)
let start = b.loadInt(0)
let end = b.loadInt(100)
let step = b.loadInt(1)
b.forLoop(start, .lessThan, end, .Add, step) { _ in
b.callFunction(f, withArgs: arguments)
}
}Basically, what this code generator is doing is: get a reference to a previously defined function within a FuzzIL program with b.randVar(ofType. function()), then try to call it inside a for loop (100 times) so that it (hopefully) triggers optimisation (Turbofan).
Extending code generation capabilities
To target the JIT compiler (one of which is Turbofan in v8), I started writing a new code generator like ForceV8TurbofanGenerator, but this time aiming for a type confusion that could yield a crash. Most type confusions I studied have the following pattern for exploitation:
function confusing_function(x) {
define_variables;
trigger_bug(x);
if (bug_triggered) {
access_OOB_array;
}
}
confusing_function(value1);
for (let i = 0; i < 10000; i++) {
confusing_function(value2);
}
confusing_function(value3);This is almost the same logic that ForceV8TurbofanGenerator has. I say almost because while it’s ensuring optimisation, it wasn’t ensuring that calls with different parameters could trigger crashes. It is important to try and trigger a crash because type confusion bugs will likely yield no crash, as we’ll see in the Proof-of-Concept later.
fileprivate func AimForTypeConfusion(_ b: ProgramBuilder) {
// Start modelling the function body
let f = b.defineFunction(withSignature: FunctionSignature(withParameterCount: Int.random(in: 2...5), hasRestParam: probability(0.4)), isJSStrictMode: probability(0.2)) { _ in
b.generate(n: 5)
let array = b.randVar(ofType: .object()) // maybe .jsArray?
let index = b.genIndex()
b.loadElement(index, of: array)
b.doReturn(value: b.randVar())
}
// End of function modelling
// Generate three random arguments for the function
let initialArgs = b.generateCallArguments(for: f)
let optimisationArgs = b.generateCallArguments(for: f)
let triggeredArgs = b.generateCallArguments(for: f)
// Initial call to the function with initialArgs
b.callFunction(f, withArgs: initialArgs)
// Definition of the for loop to force the function as "hot"
b.forLoop(b.loadInt(0), .lessThan, b.loadInt(Int.random(in: 100 ... 20000)), .Add, b.loadInt(1)) { _ in
// Call the function with different arguments while being optimised
b.callFunction(f, withArgs: optimisationArgs)
}
// Call the function with different arguments after optimisation
b.callFunction(f, withArgs: triggeredArgs)
}From the code above, a program function was generated with 5 instructions expecting to get an array from the outer scope and trying to access an index of it (with hopes that it would trigger out-of-bounds accesses). Its definition is then stored in variable f so that we can generate 3 different calls (initialArgs, optimisationArgs and triggeredArgs) with different arguments. This is to mimic the type confusion exploitation pattern shown before.
In the interest of time, I don’t want to dwell much more in all of the modifications I made to fuzzilli. But, there’s one important change I made that I think was pivotal in discovering the initial bug. This is, adding the -0 number into the JavaScriptEnvironment.swift file.
Maximising fuzzing efforts
Up until here, all of the setup work had been modifications I implemented while fuzzing. Meaning, I didn’t get to this point right from the start but rather did the following on repeat:
- Shutting down fuzzing instances
- Modified Fuzzilli code and try to improve coverage
- Restart and sync with the master fuzzer instance
During the previous process of changing fuzzing strategies and coding, I also chose different cloud providers and configurations for said fuzzing strategies. As I mentioned before, fuzzing is a constant race and if you want to beat other fuzzers, including Google’s own oss-fuzz, you’ll need to optimise code analysis while also trying to go for depth rather than breadth:
As of January 2020, OSS-Fuzz has found over 16,000 bugs in 250 open source projects.
– https://github.com/google/oss-fuzz#trophies
So, my fuzzers were started, having a leader with just a few cores:

In order to have this blog post advertisement-free, I’ll just mention that a mix of different cloud providers were used for these machines where I fuzzed for several days at a rate of £2.08/hr on average. The top speed I reached was 1710 executions per second. This speed only lasted for about an hour and as soon as more complex cases were found, the execution speed dropped down to an average of 500~600 per second. The maximum number of connected Fuzzilli workers I had at a single point in time was 62.

0 day
I’m not going to lie, the disclosure was a mess. Given that my knowledge of v8 wasn’t that extensive and that impostor syndrome kicked me in the face a few times, I was unsure if what I discovered was a security vulnerability. To be clear: at this point I had found something, but I was hesitant whether it would have any impact at all.
Honey, we’ve got a crash!
There is this thing about fuzzing that keeps you excited throughout the process; the feeling of seeing new crashes. This is something that’s both exciting and draining. It was an early Sunday morning when I jumped straight from bed onto my laptop to start triaging/analysing new crashes with some good old for loops in bash. Most of them being out-of-memory (OOM) crashes, except for one. This started with my partner high 5’ing me, cheering me up, followed by me trying to explain to her why it’s so important that the crashes number went from 247 to 248 and why that single instance mattered so much. I’m sure that by now she knows more about exploit development than she would like to. She could have avoided long explanations if in the beginning I had this simple line of code that would prevent crashing on the annoying out-of-memory crashes. This is part of the bits I added that I mentioned before which helped at a later stage to focus fuzzing (and AFL++) efforts even more. Regardless, up until that moment, the line of code to triage each and every crash would look like:
for file in $(find crashfolder/ -iname "crash*.js"); echo "[+] $file"; do /path/to/v8/out.gn/x64.release/d8 --allow-natives-syntax $file | grep -iE "error|fatal"; doneI get tired of ssh’ing into every single instance and, running it manually, so I scripted my own Telegram bot to send me test cases and some stats:
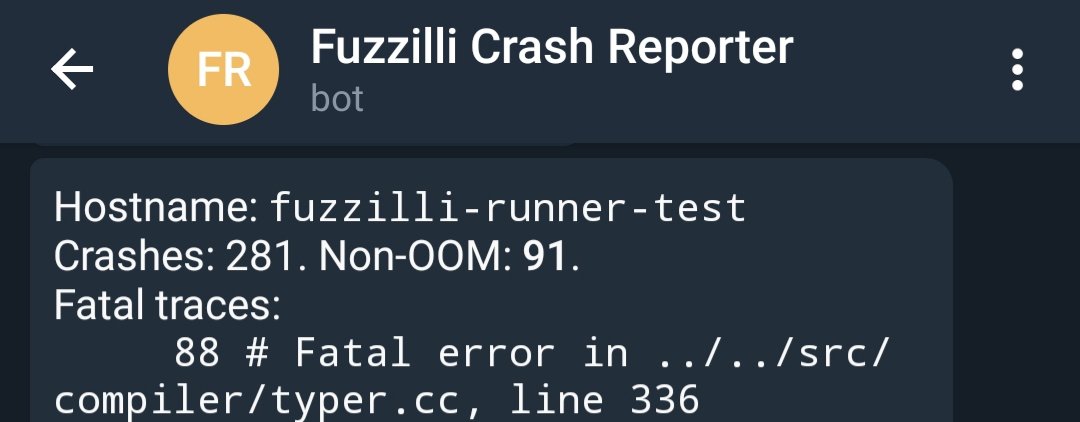
Now, what did all the previously reported non-OOM crashes have in common? To understand it, let’s see what a minimised crashing file looked like:
function crash() {
let confused;
for (let i = -0; i < 1000; i++) {
confused = Math.max(-1, i);
}
confused[0]; // anything dereferencing will crash
}
%PrepareFunctionForOptimization(crash);
crash();
%OptimizeFunctionOnNextCall(crash);
crash();Everything seems to be more or less normal except for that -0 in the for loop, feeding this variable into Math.max. By creating a test case without the -0 I could confirm that this was the issue. I got happy, really happy, because at least in v8 -0 has its own type and similar cases have been exploitable in the past, apart from being a bit of a headache for programmers. Some more analysis in a debugger together with flashbacks from fuzzing other software, I figured that it was still a safe error. If we looked at line 336 on typer.cc:
FATAL("UpdateType error for node %s", ostream.str().c_str());
It does look like it’s a safe error. At this point I’m lowkey thinking that I just hit something similar to an OOM crash, however, I wanted to find the root cause. Let’s head onto the usage of amazing tools.
Amazing world of tools
I won’t get tired of giving praise to the Chromium project and the tools they open-source and share with the world. It was instrumental in getting to know about the different options that v8’s standalone interpreter (d8) provides. Other tools that helped a lot were rr in combination with the amazing gdbgui (gdbgui supports rr out of the box) which made debugging v8 muuuuuuuch easier. Vim delivered goodness by being the alpha and omega of this research with its -d flag. This helped in seeing the first difference in typing rounds and pinpointing the root cause.
The v8 interpreter has one too many switches, and many of those related to tracing what Turbofan is doing. From analysing previous bugs and reading up on optimisation phases within v8, you learn that reductions are quite important as these might end up being assumptions that trigger type confusions. More on that later. Let’s focus on what the reductions for two test cases looked like using Vim’s -d flag; one that crashes and one that doesn’t (one that does have the -0 and one that is just 0). We run each case as follows and then compare them:
./d8 --trace-turbo-reduction --allow-natives-syntax crrash.js > crash-reduction.txt
./d8 --trace-turbo-reduction --allow-natives-syntax nocrash.js > nocrash-reduction.txt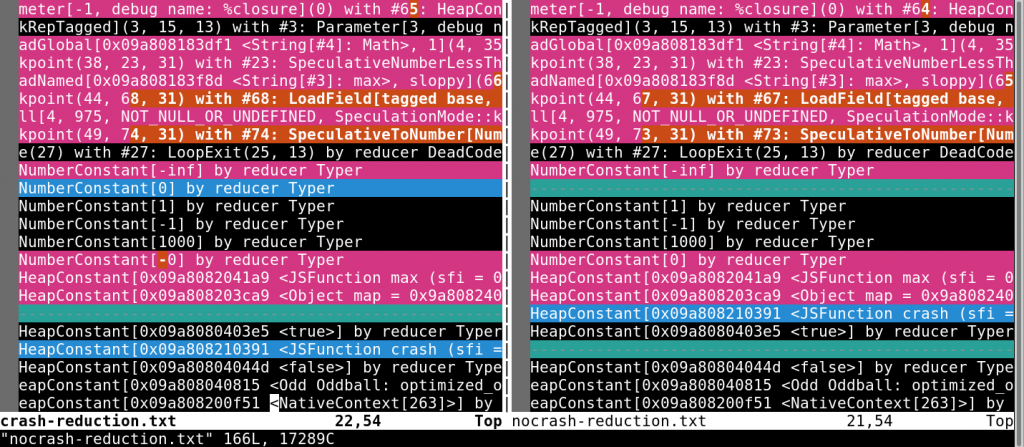
The difference is really minimal, which makes it a bit hard to spot initially. However, it does make it a lot easier for us to start digging down the rabbit hole. Why is there a NumberConstant[0] in the crashing test and what could this mean during a typer round? Let’s look at some more code. Surely the few lines before the crash should show us something:
Reduction UpdateType(Node* node, Type current) {
if (NodeProperties::IsTyped(node)) {
[... SNIP ...]
if (V8_UNLIKELY(!previous.Is(current))) {
[... SNIP ...]
}
FATAL("UpdateType error for node %s", ostream.str().c_str());
}
[... SNIP ...]It might not be clear on first sight without the SNIPs in there (it wasn’t for me at least) but what’s happening is that if previous.Is(current) fails to return true, then it’s game over and we’ll crash. What exactly does the Is(..) function do? After a bit of inspection and reading source code comments, it’s “clear” that it’s testing whether the type of previous is contained within current. For example, imagine that the previous variable is a Number type and the current variable is a NumberOrString type. Because Number is a type contained within the NumberOrString type, it would yield true. My guess in this specific case was that it’s just testing for equality between types. What’s important for us though is that for some reason we don’t know at this point, that there is a mismatch between the previously computed type(s) and the expected one(s). We’ll see more on that later.
Disclosure
You can skip this part if you’re only interested in the technical bits, but I believe there’s a few takeaways on the way I messed up the disclosure process (much to my benefit in the end).
Google provides what I see as good rules in terms of disclosing bugs. You can provide the initial crash almost straight from the fuzzer and then provide more details, analysis or a working exploit, and that would be still considered valid in the disclosure process. They take all of those as input to measure the quality of the report. Because of this, I decided to create a report with just a tiny bit of analysis straight away and send it to Google and then keep working on the bug. I reported crbug/1067415 and after some time, Jeremy Fetiveau left a couple of comments on the tweets about the bug:
FATAL in UpdateType? :)
— Jeremy Fetiveau (@__x86) April 3, 2020
I started freaking out thinking that I just naively sent an obvious “fail safe” bug. Even worse, he pointed out exactly to the previous variant of the same class of bug:
Like the recently patched NumberMin/NumberMax bug maybe? :)
— Jeremy Fetiveau (@__x86) April 3, 2020
I was destroyed and feeling dumb – I went to the ticket and reported it as a duplicate of this one, which was closed and nothing more was heard (for a few days anyways).
+0 day – Analysis
An important trait we teach at SensePost trainings came back to bite me: Don’t assume anything. Moreover, when code is an “exact” science, there’s plenty of resources that will help giving clarity to most assumptions.
I kept on digging, reading the submission rules. Turns out that a crash in a sandboxed process (like the v8 interpreter), is still something unexpected to happen. So I ran the crashing test case that I thought was a duplicate again on the latest commit and it still happened. Huh? Could it be that I was sitting on a variant of crbug.com/1063661?
Clairvoyance
At this point I thought I might have a variant of the initial bug, and there’s no better way to test for a variant than a bit of reading and 8 fuzzers. I wanted to use the newer AFL++ as it uses the concept of power schedules. To use AFL++ in v8 you’ll need the use_afl flag and some patience to find where the Chromium build is looking for AFL and translate that into the v8 build (you can either copy paste files into the folders or modify the “update” python script).
To start fuzzing with AFL++ you’ll need a corpus; aka, an initial set of test cases so that the fuzzer can start mutating and feeding these into the program. For this I manually created variations that might trigger different paths or crashes. In addition, I used a variety of power schedules across fuzzers, with a JavaScript dictionary since AFL++ is not context-aware by default. Finally, one of the fuzzing instances was using radamsa. Another night of fuzzing later, a fresh high 5 in the morning took place:

The minimised crashing test case now looked like this:
function crash() {
let confused;
for (a = 0; a<2; a++) // From AFL dictionary
for (let i = -0; i < 1000; i++) {
confused = Math.max(-1, i);
confused[0];
}
}
%PrepareFunctionForOptimization(crash);
crash();
%OptimizeFunctionOnNextCall(crash);
crash();At this point it was clear that I was onto something that wasn’t meant to happen. As for the crash, hitting a “breakpoint trap” just means that we hit a breakpoint just as you would do in a debugger, but outside of one. This means that the compiled code had a way to still safely break when something unexpected happened.
Previously we saw how this bug crashed when a check in the source code realised that the previous type isn’t the current type. In the generated compiled code it is somewhat similar to that as there are still checks for when the result is non-satisfactory, it will run through an int3 instruction known as a breakpoint:
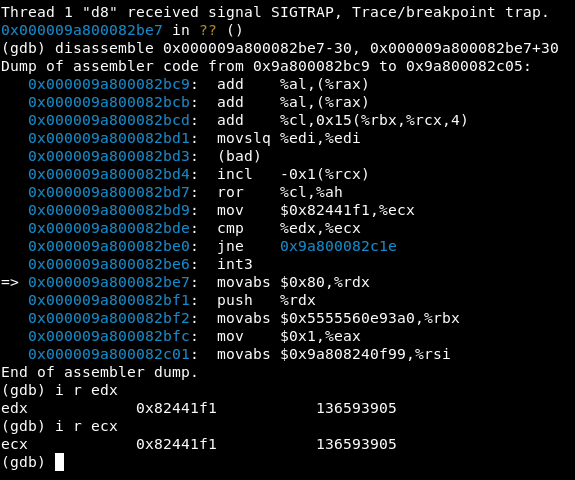
As we can see, there’s an int3 instruction there (a breakpoint) in the JIT’d code that was executed due to a safe bailout (cmp %edx, %ecx; jne 0x9a800082c1e;). This is to prevent something more harmful from happening, for example, someone trying to exploit the type confusion.
This bailout should not to be confused with a deoptimisation bailout. If you want to hear a very good explanation on the latter please refer to Franziska Hinkelmann’s talk on JavaScript engines, skip to 15:57 for the bailout explanation.
Analysis
Intro to NumberMax function
To perform the analysis, I relied on the amazing combination of gdbgui and rr, as gdbgui can step backwards in a debugging session as well. I’ll spare you the one too many breakpoints I placed on all the backtraces, and instead focus on the core of the bug happening in the NumberMax function within the operation-typer.cc file (this can also be done on the NumberMin function). Taking into account that the Math.max JavaScript call will trigger the typing run on the NumberMax function, let’s look at the following snippet of code:
number_left = -1;
number_right= -0;
Math.max(number_left, number_right);From this JavaScript snippet we can infer what would be the type for the initial numbers and what will be fed into the relevant operation-typer.cc function. Within v8’s source code, the types for these will be referred to as left hand side and right hand side nodes: lhs & rhs. The NumberMax typing function does not really trust initial assumptions and performs a couple of checks before doing any typing (I think these would only be triggered if debug checks and slow checks are enabled at compilation time):
Type OperationTyper::NumberMax(Type lhs, Type rhs) {
DCHECK(lhs.Is(Type::Number()));
DCHECK(rhs.Is(Type::Number()));Next it will perform a couple of more checks against None or NaN (Not a Number) types:
if (lhs.IsNone() || rhs.IsNone()) return Type::None();
if (lhs.Is(Type::NaN()) || rhs.Is(Type::NaN())) return Type::NaN();Basically, if either one of the variables that are fed into Math.max(v0, v1) is of type None or NaN, the function will return a type of None or NaN depending on the case. Let’s keep analysing, we’re almost there:
if (!lhs.Is(cache_->kIntegerOrMinusZeroOrNaN) ||
!rhs.Is(cache_->kIntegerOrMinusZeroOrNaN)) {
return Type::Union(type, Type::Union(lhs, rhs, zone()), zone());
}What we can see from this snippet is that if either the left number or right number is not in the kIntegerOrMinusZeroOrNan type then the function will immediately return a Union of the types of lhs and rhs. However, both satisfy it in the example, as lhs is of type Integer and rhs is of type MinusZero, so this is not executed.
The importance of -0 in NumberMax
As mentioned earlier, -0 and its computational challenges are a headache for programmers, and v8 is no exception. Because of the significance of -0, v8 needs to create a specific type for it in order to generate well optimised code. In the NumberMax function, the first consideration if any of the inputs are -0, is shown below:
bool const lhs_maybe_minus_zero = lhs.Maybe(Type::MinusZero());
bool const rhs_maybe_minus_zero = rhs.Maybe(Type::MinusZero());
lhs = Type::Intersect(lhs, cache_->kInteger, zone());
rhs = Type::Intersect(rhs, cache_->kInteger, zone());What this code is saying is; let’s keep a reference whether one of the numbers is maybe the MinusZero type (which rhs is) and then, make an intersection between the type of rhs with kInteger and, separately, the type of lhs the kInteger type as well.
Common sense tells us that for the case of the type of rhs, which is MinusZero, it should be within the Integer range, right? After all, MinusZero is a number too. Let’s see if the kInteger type contains MinusZero:

We can see in the previous image that if an integer is to contain the MinusZero type, it is explicitly Union‘d to it. Therefore the following line in NumberMax will yield a NoneType due to the intersection being empty, since kInteger does not contain the MinusZero type (remember, rhs in our analysis):
rhs = Type::Intersect(rhs, cache_->kInteger, zone());If this is propagated it would effectively mean that the MinusZero type has been lost for future typing rounds (and that rhs has no type now due to the empty intersection). We don’t really need to go too far to check whether this has impact as the function itself makes use of this computed type:
bool maybe_minus_zero = lhs_maybe_minus_zero || rhs_maybe_minus_zero;
if (!lhs.IsNone() || !rhs.IsNone()) {
double min = std::max(lhs.IsNone() ? -V8_INFINITY : lhs.Min(),
rhs.IsNone() ? -V8_INFINITY : rhs.Min());
double max = std::max(lhs.IsNone() ? -V8_INFINITY : lhs.Max(),
rhs.IsNone() ? -V8_INFINITY : rhs.Max());What happens in this portion of code is that the value range to be returned by NumberMax is being calculated, since the Math.max function might return different results within the range of the two inputs. This is done by computing the maximum of the minimums and the maximum of the maximums, for both sides (lhs & rhs). To try and be more clear using pseudo-code, the returned range would be calculated as:
maximum_minimums = MAX(lhs.min(), rhs.min());
maximum_maximums = MAX(lhs.max(), rhs.max());
Range(maximum_minimums, maximum_maximums);We know that the maximum of -1 and -0 is indeed -0 but, if we look closely at the following lines of code in the NumberMax function, note that rhs now doesn’t have a type because of the previous intersection:
double max = std::max(lhs.IsNone() ? -V8_INFINITY : lhs.Max(),
rhs.IsNone() ? -V8_INFINITY : rhs.Max());It is possible to see that, due to rhs.IsNone() returning true, -V8_INFINITY will be taken into account instead of the expected -0 value of rhs.Max(). Thus it will run the max function with the following values std::max(-1, -V8_INFINITY) returning -1 as the maximum, which is not the expected computation as the returning range will now be computed as Range(-1, -1). This doesn’t consider the -0 case, either in the range type, or in the returned type at the end.
type = Type::Union(type, Type::Range(min, max, zone()), zone());
maybe_minus_zero =
maybe_minus_zero && (min < 0.0 || (min == 0.0 && lhs_maybe_minus_zero &&
rhs_maybe_minus_zero));
}
if (maybe_minus_zero) {
type = Type::Union(type, Type::MinusZero(), zone());
}
return type;
}The rest of the code sets the type to a Union of the current computed type where Range(min, max) then tries to calculate whether the function might have the MinusZero type which is now lost. This means that the calculation trying to calculate if it is MinusZero will now fail and return false, finally losing the MinusZero type for subsequent typing rounds.
Visual confirmation
Coming back to turbolizer and running the minimised test case we can easily observe how the range is indeed not considering MinusZero during the TurboFan Typer phase (TFTyper) on Node 121:
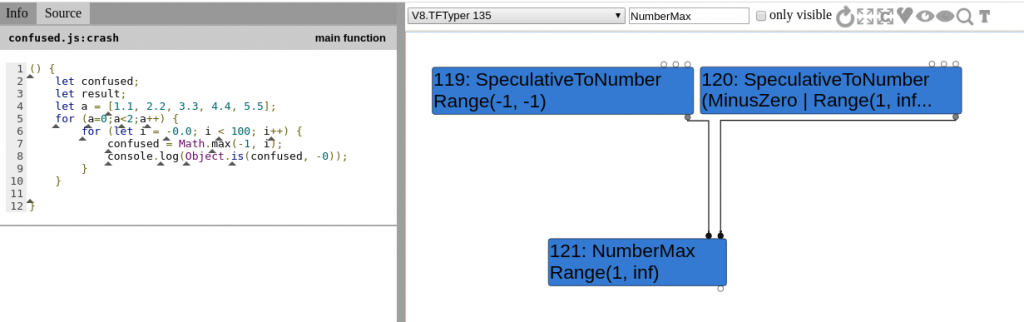
MinusZero, ignoring node 120.As we have access to the source code it is possible to both modify and debug the code. In my case, I added some printf calls in order to output the calculated min and max values on screen. This was a minimal change that required little effort; however, I also wanted to check what the types of rhs and lhs were at different stages, just to confirm my assumptions of the type confusion. To do this I first gathered all the types in the type-cache.h file:
Next, I used some awkward awk to output gdb commands that would give me a list of the types that are active on rhs or lhs or their union at a certain breakpoint (more on executing gdb commands on breakpoints here). I would then store each of the typing runs in separate files depending on the status of the run:
As a last step, I cleaned up the output and left only the types that yielded true when executed within gdb, storing these in separate files depending on either the variable (lhs, rhs) or the return type for the N-th call to NumberMax:
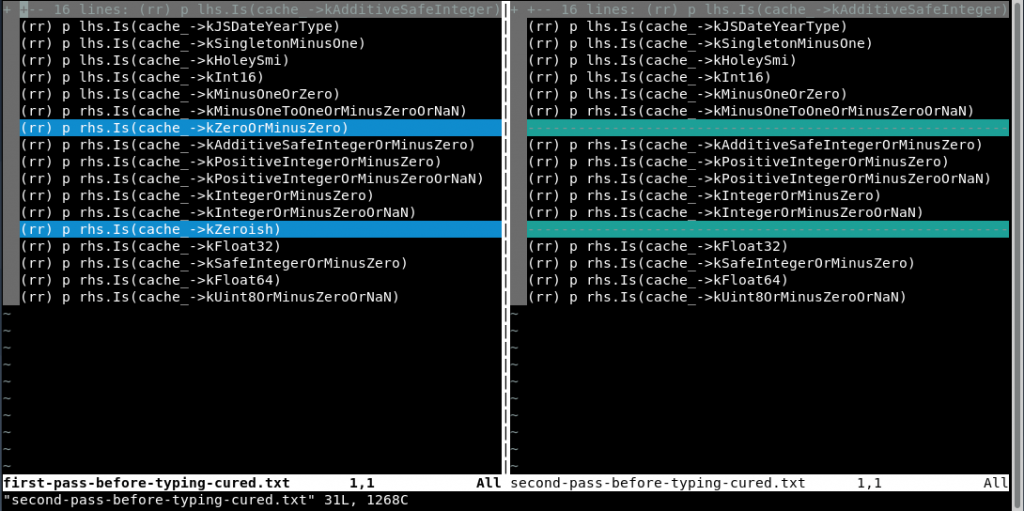
As we can see in the vim diff, ZeroOrMinusZero and the Zeroish types are not in the second NumberMax pass. By itself, this analysis might or might not mean that something is wrong with the types, but it’s a way to correlate with source code analysis and turbolizer that a type has been lost.
Triggering the type confusion
After playing around with the newly created test case I found out that there were a few combinations that did not make the v8 interpreter crash. As my luck would have it, one of the statements that did not make it bail out was the function Object.is, which allows one to compare the values of two objects making a distinction between -0 and +0.
function opt() {
for (a = 0; a<1; a++) // From AFL dictionary
for (let i = -0; i < 1; i++) {
res = Object.is(Math.max(-1, i), -0);
}
return res;
}
%PrepareFunctionForOptimization(opt);
console.log(opt());
%OptimizeFunctionOnNextCall(opt);
console.log(opt());If all of our previous analysis was right, after optimisation -0 will no longer be returned by the Math.max function and then, the function should return false, having two different outputs while the same code is being executed twice.
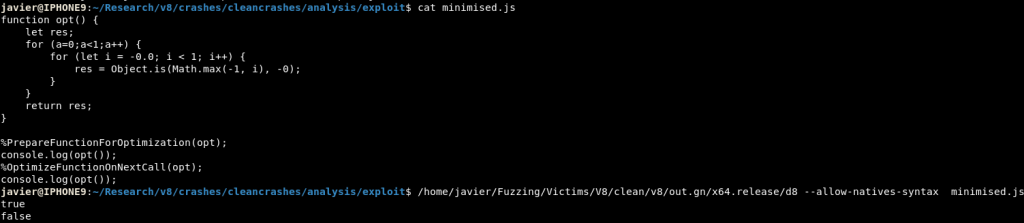
This is the effect of the Type Confusion that I had found.
Patch thoughts
The process of implementing a patch for these bugs does not only consider security posture, but also performance impact. In fact, the comment on the commit that fixed the issue, read as follows:
[…] They try to be very precise about when the result can be -0, but do so incorrectly. I’m changing the code to just do the simple thing instead. Let’s see how that affects performance.
https://chromium.googlesource.com/v8/v8.git/+/4158af83db7bab57670a9254b766df784cd8a15e
It might seem like common sense to think about performance, but when looking at everything from a security perspective it’s easy to lose that perspective. In the bug tracker I proposed the following fix (in the bug tracker there’s a typo which I fixed here):
bool const lhs_maybe_minus_zero = lhs.Maybe(Type::MinusZero());
bool const rhs_maybe_minus_zero = rhs.Maybe(Type::MinusZero());
if (lhs_maybe_minus_zero)
lhs = Type::Union(lhs, Type::MinusZero(), zone());
if (rhs_maybe_minus_zero)
rhs = Type::Union(rhs, Type::MinusZero(), zone());
lhs = Type::Intersect(lhs, cache_->kInteger, zone());
rhs = Type::Intersect(rhs, cache_->kInteger, zone());I tried to fix the MinusZero type to either the right or left hand side of the operation to prevent it from yielding a NoneType later. While this prevented the crash, it was by far not the most optimal solution. In my proposed patch there’s still the issue of why forcing the Union prevents crashing, since MinusZero doesn’t intersect with kinteger later; but let’s ignore that until a few paragraphs later. The final patch implemented looked like this:

As we can see, this is a much more elegant and simple solution, removing all the complexities at a later stage, although the idea is still the same. If the type of any of the right or left hand side operands are MinusZero then perform a Union with the type variable, as this one will be returned and union’d with the Range type below. But why did I choose a Union for each of the lhs and rhs variables? The answer is in the range calculation lines:
if (!lhs.IsNone() || !rhs.IsNone()) {
double min = std::max(lhs.IsNone() ? -V8_INFINITY : lhs.Min(),
rhs.IsNone() ? -V8_INFINITY : rhs.Min());
double max = std::max(lhs.IsNone() ? -V8_INFINITY : lhs.Max(),
rhs.IsNone() ? -V8_INFINITY : rhs.Max());In the analysis of the bug we saw how the range seemed to be incorrectly calculated due to the intersection of types (kInteger & MinusZero) resulting on a NoneType which propagated to the std::max function. Again, this might seem like a “wrong” calculation but bear in mind that the type now still keeps the MinusZero so we can assume that the range also considers the -0 case. Let’s see that in turbolizer:

MinusZero type from node 105Here we can see that the final patch propagates the MinusZero type from node 105 to node 106 which didn’t happen previously.
Update: After writing this, the code has changed again on the NumberMin and NumberMax functions: they have kept it really simple now!
Conclusions
We’ve seen how to find and analyse vulnerabilities in major software such as v8, going from the details of the tooling to use such as fuzzers and debuggers into the daunting area of diving into large code bases.
All this research is to be taken in a “step-by-step” approach where everything is defined and split in smaller goals such as: understanding Fuzzilli, building v8, understanding v8’s code base, understanding common vulnerabilities, etc.
Fuzzing complex software, specifically software that is bound to intricate parsing routines requiring valid syntax, can be daunting at first. But the complexity is also an advantage as it means there are many undiscovered bugs within the source code. Therefore it makes sense to spend time analysing a code base and setting up fuzzers in order to take on the challenge of discovering vulnerabilities.
Furthermore, there are plenty of resources nowadays to get a jump start in browser security; see the many mentions throughout the blog post about fuzzilli and the tools provided by the v8 team.
Something missing in this blog post is a way to exploit this bug like in some of the exploits shown in the resources section below. As I mentioned in previous blog posts, new exploit mitigations (boundary checks) would require another bit of research to find ways to first wrap up the type confusion so that we can trigger it to return “true” when the optimiser assumes it can never return “true” and then, find a way to circumvent the bounds checking to read/write past a predefined array.
If I had to give one main take-away from this research, it is patience and persistence, as these were key on spending the time to understand the different platforms and technologies.
Resources
- https://bugs.chromium.org/p/project-zero/issues/detail?id=1710
- https://abiondo.me/2019/01/02/exploiting-math-expm1-v8/
- https://doar-e.github.io/blog/2019/01/28/introduction-to-turbofan/
- https://doar-e.github.io/blog/2019/05/09/circumventing-chromes-hardening-of-typer-bugs/
- https://www.gdbgui.com/
- https://rr-project.org/